SLA não é um contrato jurídico. É bússola de confiabilidade.
Medir Uptime não basta, no ProdOps e no ODD (Observability Driven Design), indicadores existem para direcionar evolução, não para preencher relatórios. Quando falamos de SLA, estamos falando aqui sobre toda a cultura, que envolve SLO, SLI e Error Budget.
SLA do jeito novo (e porque não falha)
Um dos principais problemas que o ProdOps busca resolver é o antigo atrito no alinhamento entre TI e Negócio. Durante anos, as empresas trataram confiabilidade como responsabilidade exclusiva da área técnica, enquanto o negócio ficava apenas cobrando resultados. Esse modelo criou uma divisão artificial, em que cada lado falava uma língua diferente.
A mudança começa quando entendemos que SLA não é um contrato de cobrança entre áreas, mas sim um compromisso conjunto de produto. Muitas organizações já perceberam que transformar o SLA em um acordo explícito e transparente dentro da cultura SRE gera enormes benefícios:
- O negócio passa a enxergar o SLA como garantia de valor entregue ao cliente, e não como jargão técnico.
- A TI deixa de medir sucesso apenas por uptime, e passa a relacionar indicadores técnicos com impacto direto no usuário.
- O diálogo entre times fica menos baseado em cobranças e mais baseado em decisões compartilhadas: lançar uma nova funcionalidade agora ou investir em resiliência?
No ProdOps, esse alinhamento vai além: o SLA se torna a bússola que guia tanto evolução de produto quanto confiabilidade operacional. E quando conectamos isso à prática de Observability Driven Design (ODD), o compromisso deixa de ser abstrato e passa a ser observável e mensurável em produção, com métricas, SLOs e error budgets claros.
No fim, o que antes era motivo de conflito (TI defendendo estabilidade e negócio cobrando velocidade) se transforma em métrica compartilhada de sucesso.
SLA como contrato entre TI e negócio
A maioria dos profissionais, especialmente os técnicos, tende a seguir as definições de SLA presentes nas documentações das grandes clouds (AWS, GCP e Azure). Embora úteis como referência operacional, essas definições raramente são aplicadas de forma integrada ao negócio, criando um viés limitado que impede a maximização do verdadeiro potencial desse modelo de gestão.
Vejamos um resumo do que se prega no mercado:
Microsoft Azure (definições em documentações e certificações)
- Conceito geral: O SLA é um compromisso formal da Microsoft com o cliente sobre disponibilidade e desempenho do serviço, geralmente expresso como percentual de uptime (como 99,9%).
- Componentes comuns:
- Percentual de disponibilidade.
- Créditos de serviço como compensação caso o SLA não seja cumprido.
- Impacto de configurações e níveis de serviço sobre a garantia .
- Termos técnicos em certificações (como AZ-900):
- SLA é definido como um acordo contratual de nível de serviço entre provedor e cliente, que pode gerar consequências financeiras caso não seja atendido. Documentação Oficial.
- Pergunta exemplo (AZ-900): “O que é garantido em um SLA do Azure?” —> resposta correta: uptime (disponibilidade) .
Amazon Web Services (AWS)
- Definição: SLA é um contrato entre fornecedor e cliente, que estabelece níveis de serviço com métricas como uptime, tempo de resposta, e prevê ações (como créditos ou descontos) se os níveis não forem cumpridos. Documentação Oficial.
- Aspecto geral: Centrado em disponibilidade, medido com “Monthly Uptime Percentage”, com créditos de serviço como compensação.
Google Cloud Platform (GCP)
- Visão geral do SLA: Também define um compromisso formal de uptime mensal (SLO), com a possibilidade de créditos financeiros quando não cumprido. Documentação Oficial e capítulo específico do SRE Book (livro que definiu e contextualizou o papel do SRE e a cultura envolvida).
- Distinção importante: GCP enfatiza a diferença entre SLO (objetivo interno de confiabilidade) e SLA (compromisso contratual, com compensação financeira) .
A maioria dos profissionais, especialmente os técnicos, tende a seguir as definições de SLA presentes nas documentações das grandes clouds (AWS, GCP e Azure). Por exemplo, nas certificações da AWS, como o AWS Certified Cloud Practitioner (CLF-C02), espera-se conhecimento de termos fundamentais da nuvem, incluindo Service Level Agreement (SLA) e conceitos relacionados (SLO, MTTR), conforme o guia oficial do exame; em níveis mais avançados, como o AWS Certified Solutions Architect (SAA-C03), o conteúdo explora o Well-Architected Framework e práticas de confiabilidade que implicam definição e desenho de SLAs/SLOs para arquiteturas de produção. Essas referências são valiosas como base operacional, mas quando aplicadas isoladamente, sem vincular o SLA a métricas de negócio e à prática de Observability Driven Design, acabam gerando um viés que limita a capacidade de usar esse modelo de gestão para tomar decisões reais de produto e operação.
ODD como prática para materializar SLA
Muitas equipes ainda têm dificuldade em contextualizar o que é SLA e distinguir claramente de SLO e SLI e isso é completamente natural, pois a confusão surge principalmente na prática diária. Uma dica (como gatilho) que costumo dar para evitar misturar os conceitos é pensar assim: SLA é quase sempre um compromisso binário, ou você cumpre o percentual ou absoluto acordado, ou não cumpre. Quando você percebe que está tentando medir algo de forma gradual, com números específicos e contínuos, provavelmente está se confundindo: nesse caso, o que você está definindo é mais um SLO ou um SLI, que são métricas de desempenho usadas para monitoramento interno, e não o contrato formal de serviço.
Definição simplificada:
| Conceito | O que é | Métrica típica | Como pensar | Exemplo |
|---|---|---|---|---|
| SLA (Service Level Agreement) | Compromisso formal com o cliente | Percentual ou absoluto | Binário: cumpre ou não cumpre | “99,9% de uptime por mês” |
| SLO (Service Level Objective) | Objetivo de confiabilidade interno | Percentual, tempo, contagem | Meta interna que guia decisões | “95% dos pedidos processados em ≤ 2s” |
| SLI (Service Level Indicator) | Métrica concreta que mede desempenho | Métrica real observável | Indica se SLO/SLA estão sendo cumpridos | “Latência média do endpoint de checkout = 1,8s” |
Gancho para não confundir:
SLI = métrica real: mostra se você está dentro do objetivo.
SLO = objetivo interno: define metas graduais.
SLA = contrato: cumpre ou não cumpre.
North Star com o negócio
O framework North Star pode ser extremamente útil para guiar a definição de SLOs dentro de uma abordagem de ProdOps ou Observability Driven Design. Ao identificar a métrica central que reflete o valor entregue ao usuário, a chamada North Star Metric, é possível derivar objetivos de confiabilidade diretamente alinhados com o impacto de negócio.
Um segundo gatilho que costumo utilizar é extrair o SLA a partir de SLOs previamente definidos em conjunto com o negócio. Essa abordagem torna mais fácil identificar janelas de atuação sobre indicadores específicos, permitindo que os SLOs guiem a criação de contratos de serviço mais realistas e acionáveis, ao invés de começar por um SLA de alto nível genérico.
Por exemplo, em uma plataforma de grupos de compra de um e-commerce, podemos provocar o time de negócio a refletir sobre quais pontos da jornada são realmente críticos, priorizando o mais importante primeiro. Dessa forma, eles conseguem definir expectativas concretas, como ser notificados sempre que houver uma inconsistência relevante, mesmo que o problema ainda esteja sendo investigado, garantindo que saibam que o time técnico capturou a situação e está atuando sobre o problema, transformando indicadores em compromissos reais de operação.
Extraindo o SLO de uma Event Storming
Durante o mapeamento de eventos em uma sessão de Event Storming, é extremamente valioso provocar o time de negócio a escolher qual evento é mais crítico e em que situação e janela de tempo ele deveria ser medido. Esse exercício não apenas prioriza o que realmente importa para o usuário, mas também fornece uma visão clara de como transformar essas prioridades em SLOs concretos. A partir daí, já é possível desenhar dashboards e métricas alinhadas, que guiarão o time de desenvolvimento na implementação do serviço, garantindo que cada decisão técnica esteja diretamente conectada aos objetivos de negócio e aos compromissos de confiabilidade previamente acordados.
Vejamos como é simples:
Passo 1
Durante a sessão de Event Storming, alguns eventos de domínio naturalmente se destacam por sua importância. Esse é o momento ideal para afunilar prioridades e, pelo menos, identificar um SLO inicial que capture o que realmente importa para o negócio. Mesmo que ainda não se tenha todos os detalhes, esse ponto de partida permite começar a monitorar e guiar a implementação, garantindo que as decisões técnicas estejam alinhadas com os objetivos críticos do produto.
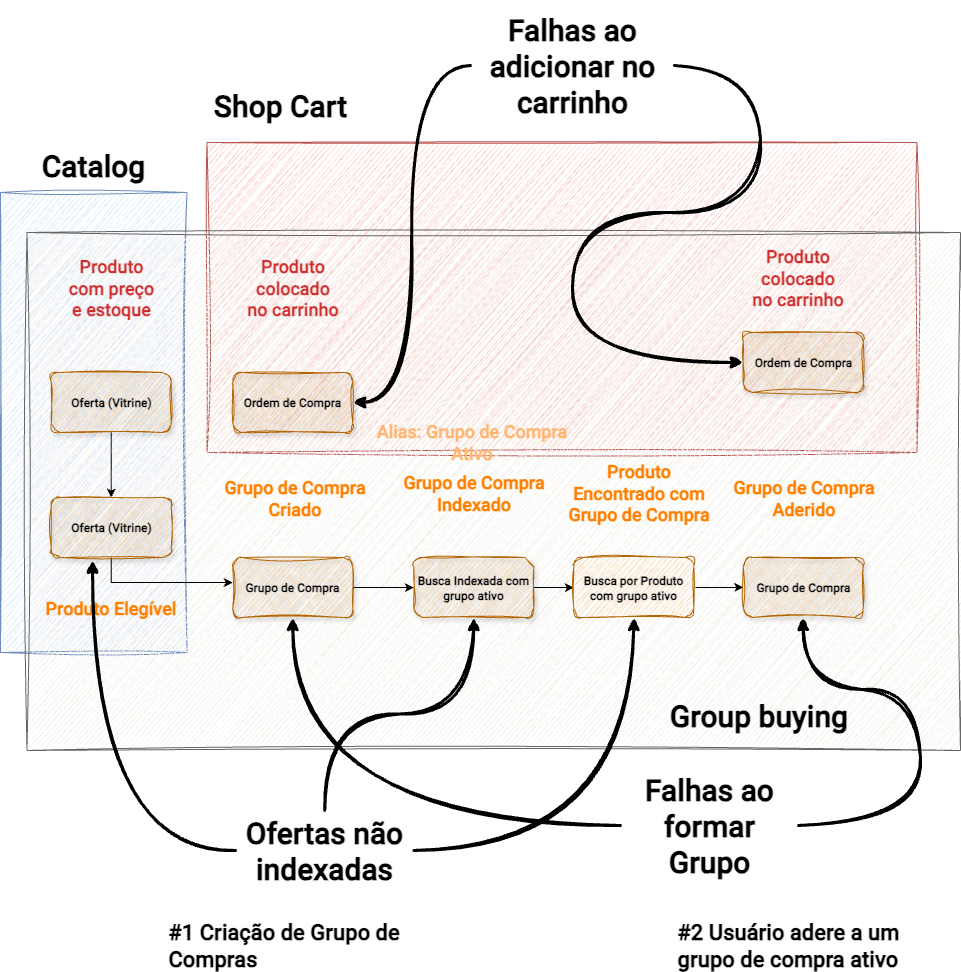
Passo 2
Durante o mapeamento dos eventos e na definição de como cada evento será medido, é importante também separar os contextos e domínios. Isso ajuda a limitar o escopo de atuação do time de negócio, incentivando-os a pensar dentro de uma “caixa” com fronteiras bem definidas, evitando confusão ou sobreposição de responsabilidades. Com essa organização, fica mais fácil derivar SLOs claros e acionáveis, alinhados a cada domínio específico, e criar métricas que realmente reflitam o impacto no negócio.
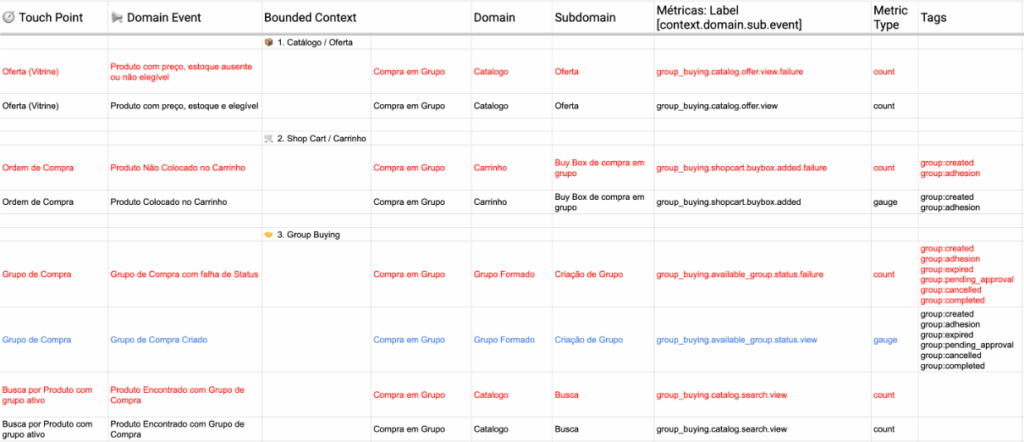
Passo 3
Uma abordagem prática para prototipar SLOs e dashboards é utilizar ferramentas como o DataDog, líder de mercado segundo o Gartner, mesmo antes de haver implementação real de uma nova feature ou negócio. Durante esse protótipo, é possível simular a ingestão de dados via API, criando métricas e eventos fictícios que reproduzam o comportamento esperado. Dessa forma, o time consegue visualizar e validar dashboards, SLOs e SLIs, testar alertas e definir prioridades com o negócio, sem depender de código pronto ou produção ativa, acelerando o alinhamento entre times de produto e operação.
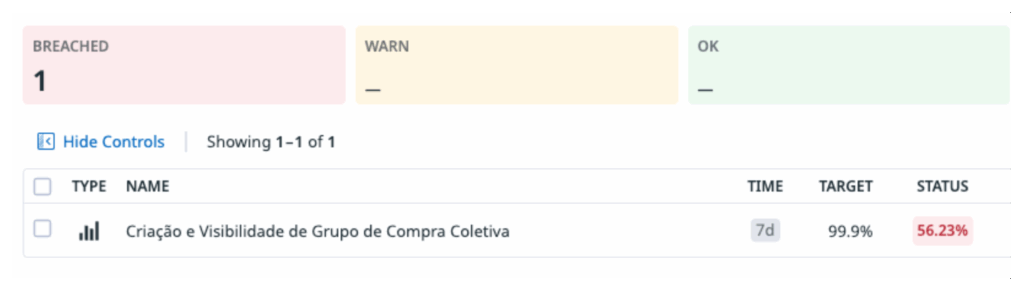
Esse passo pode ser realizado após a sessão de Event Storming, mas se for possível fazê-lo durante as discussões, ele enriquece ainda mais a sessão e fortalece o trabalho de Observability Driven Design (ODD). A ideia de sair da sessão com uma North Star, aqui entendida praticamente como um SLO inicial, serve para engajar os times e criar uma conexão concreta com a mentalidade SRE, que não se limita a observar métricas, mas também a agir e intervir proativamente. Essa prática transforma discussões conceituais em compromissos tangíveis, alinhando produto, operação e confiabilidade desde o início do desenvolvimento.
Passo 4 e complementar
A partir desse ponto, é possível extrair diversos SLIs que garantam o monitoramento e acionamento corretos, cobrindo o SLO definido. Além disso, permite mapear todo o ecossistema envolvido, identificando dependências e áreas críticas que precisam ser observadas e protegidas, mesmo quando múltiplos serviços e times estão envolvidos, garantindo que o compromisso de confiabilidade seja efetivamente cumprido.
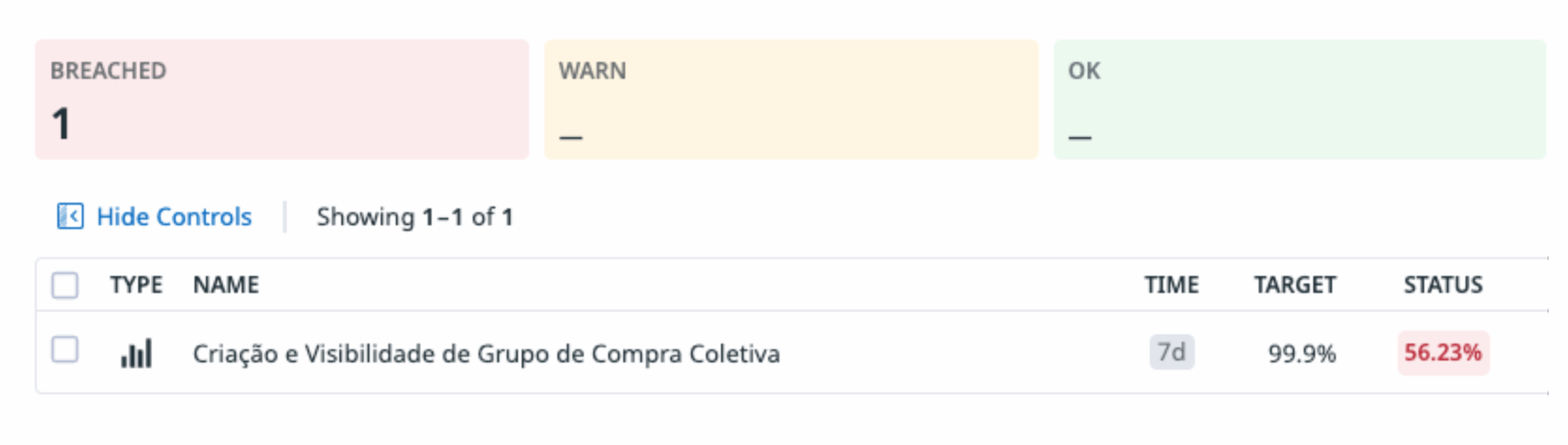
No DataDog o SLI é chamado de Monitor:
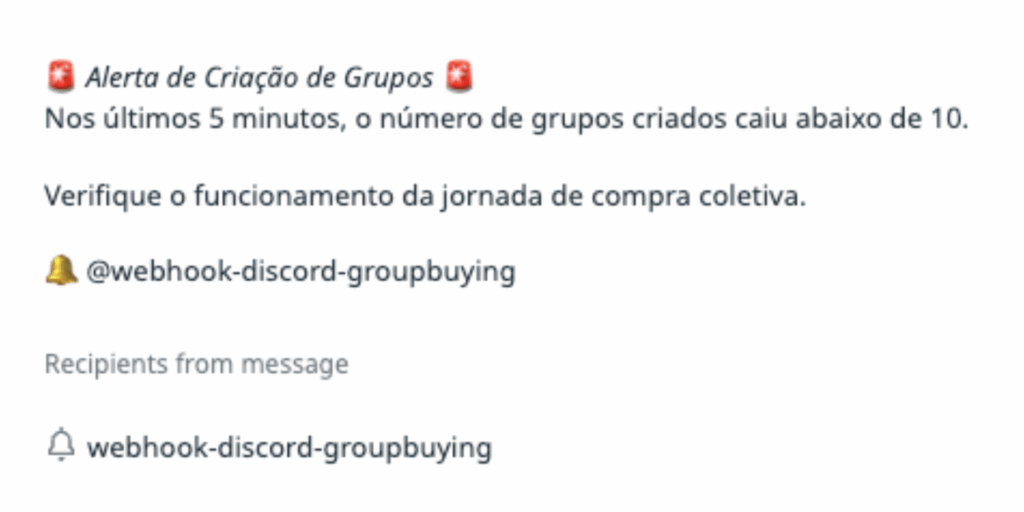
Extraindo o SLA a partir do SLO
A partir desse SLO, podemos derivar um SLA que faça sentido como compromisso formal com o negócio ou com os usuários. Uma sugestão:
SLO: Criação e visibilidade de grupos de compra coletiva com janela de 7 dias, target de 99,9%.
SLA derivado:
“O serviço garante que 99,9% dos grupos de compra criados e visíveis estarão disponíveis e acessíveis para os usuários durante a janela de 7 dias. Caso o indicador fique abaixo do target, o time compromete-se a investigar a inconsistência, notificar o negócio e tomar ações corretivas, garantindo que as falhas sejam tratadas proativamente.”
💡 Observações:
- O SLA transforma o objetivo interno do SLO em um compromisso de serviço visível para o negócio.
- Ele deve incluir ações concretas caso o SLO não seja cumprido (ex.: alertas, investigação, correção).
- Mantém alinhamento entre expectativa do usuário/negócio e operação técnica.
No contexto de ProdOps e Observability Driven Design (ODD), a definição de SLA, SLO e SLI deixa de ser apenas um conceito técnico e passa a ser um compromisso de produto concreto, alinhado ao negócio e guiando decisões de operação e desenvolvimento. Sessões de Event Storming ajudam a identificar os eventos críticos do domínio, permitindo derivar SLOs iniciais e visualizar a North Star do produto, criando conexão entre times de produto, negócio e operação. A partir desses SLOs, é possível extrair diversos SLIs para monitoramento efetivo, prototipar dashboards e simular alertas mesmo antes da implementação real, garantindo que o ecossistema envolvido esteja coberto e que o time possa agir proativamente. Essa abordagem transforma métricas em decisões acionáveis, promovendo alinhamento, engajamento e confiabilidade desde as primeiras etapas do desenvolvimento.