Papéis e Funções
Publicação da série sobre as diversas funções e posições em uma equipe de ProdOps, juntamente com as adaptações que o ProdOps faz no fluxo e na estrutura organizacional:
Literatura preliminar
Hierarquia de Cargos e Papéis
Expansão do Squad com Times Fixos e Times Virtuais
Especialidades ProdOps
ProdOps Tracker
ProdOps Specialist
ProdOps Quality Engineer
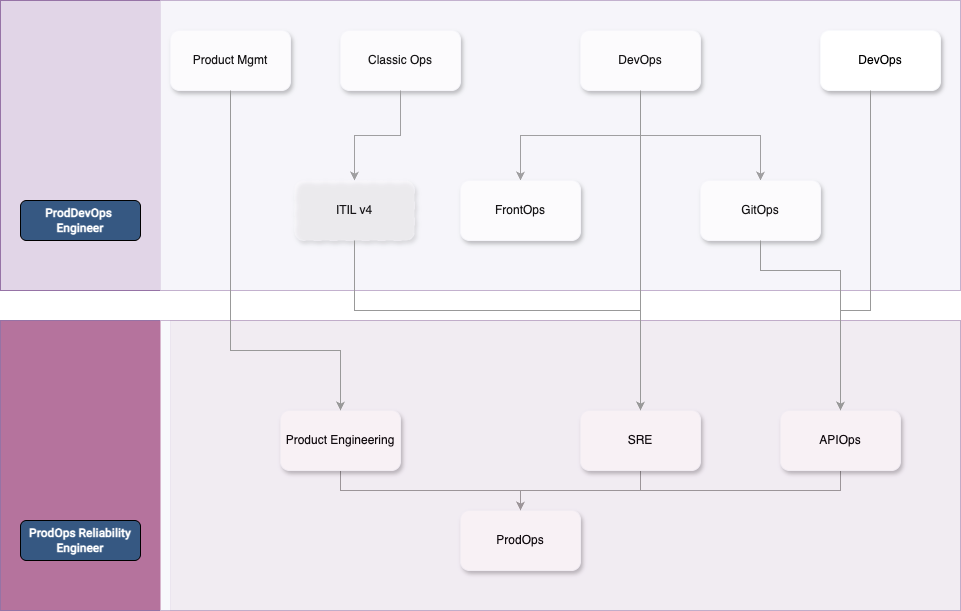
ProdDevOps Engineer
ProdOps Reliability Engineer
ProdOps Manager
Tech Product Manager
Engenheiro que observa tudo
O Engenheiro de Confiabilidade ProdOps (PRE – ProdOps Reliability Engineer) representa uma evolução estratégica na engenharia de software, integrando práticas de qualidade, operações e produto para garantir a confiabilidade contínua de sistemas digitais. Essa função amalgama as responsabilidades do Engenheiro de Qualidade ProdOps, ProdDevOps, Site Reliability Engineer (SRE) e APIOps, formando um profissional completo e adaptável às demandas modernas de desenvolvimento e operação de produtos digitais.
Em meio a um ecossistema cada vez mais fragmentado por jornadas técnicas paralelas — como segurança (Security Engineering), gestão de plataformas (Platform Engineering), Compliance, operações de dados e governança de APIs — o Engenheiro de Confiabilidade ProdOps atua como um ponto de convergência entre áreas que frequentemente caminham de forma desarticulada. Essas carreiras, embora críticas, muitas vezes apresentam sobreposições de responsabilidades, lacunas de comunicação e um volume significativo de aprendizado técnico distribuído, o que dificulta a clareza sobre “quem cuida do quê”.
Cabe ao PRE orquestrar esse cenário complexo, coordenando prioridades, integrando disciplinas e promovendo um modelo simples e rastreável de confiabilidade contínua. Sua missão não é acumular tudo, mas harmonizar a especialização com a fluidez operacional, garantindo que o avanço tecnológico da empresa ocorra com segurança, estabilidade e alinhamento aos objetivos estratégicos do negócio.
Amplitude de Carreira
Na especialidade de ProdDevOps, já estabelecemos uma base sólida a partir das competências tradicionais do DevOps, como automação, infraestrutura como código, CI/CD e observabilidade. No entanto, à medida que essas práticas evoluem e se entrelaçam com outras disciplinas organizacionais, surgem áreas paralelas e complementares que se transformam em especialidades próprias, com escopos tão complexos que exigem dedicação quase exclusiva. Isso leva a uma bifurcação natural nas carreiras técnicas, onde profissionais são, muitas vezes, forçados a se aprofundar intensamente em uma trilha específica, acabando por relegar o desenvolvimento contínuo em outras frentes.

Um exemplo claro desse movimento é a ascensão da APIOps, uma disciplina emergente que nasce da fusão entre os princípios do GitOps e as práticas de API Management. A APIOps não se limita à entrega técnica de interfaces: ela estabelece uma estrutura completa para o ciclo de vida de APIs, com governança, versionamento, observabilidade, segurança, automação e integração contínua como blocos fundamentais. Esse conjunto de building blocks cria um modelo operacional próprio, necessário para sustentar a evolução coordenada de plataformas digitais em escala empresarial.
Dentro do ProdOps, a APIOps representa não apenas uma especialização técnica, mas uma engrenagem essencial na construção de ecossistemas interoperáveis e confiáveis, onde APIs deixam de ser apenas meios de integração e passam a ser produtos estratégicos com valor mensurável para o negócio.
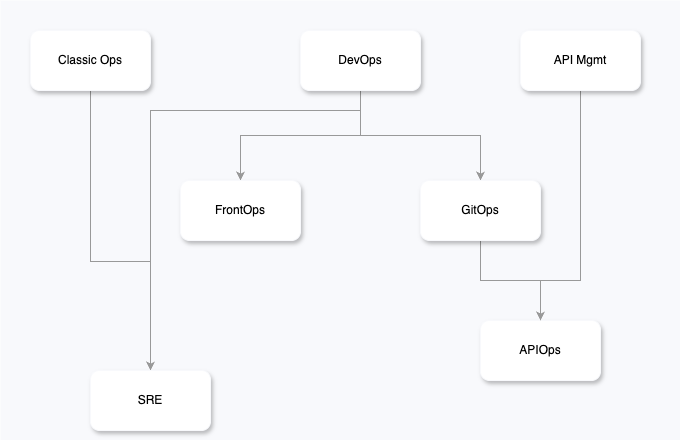
Outra especialização que emergiu ao longo do tempo e hoje é amplamente consolidada é o SRE (Site Reliability Engineering) — considerado por nós como o “ProdOps do Google”. Embora frequentemente percebido como uma abordagem puramente técnica voltada à confiabilidade de sistemas, o SRE é, na verdade, um modelo operacional completo, profundamente integrado à lógica de produto e ao ciclo de vida do negócio.
No Google, o SRE não apenas garante que os sistemas estejam disponíveis e escaláveis; ele atua desde a concepção de hipóteses de oportunidade, participa da definição de requisitos não funcionais, orienta o design com foco em resiliência e transforma métricas como SLOs e SLIs em ferramentas de governança para tomada de decisão em tempo real.
É um modelo que não separa confiabilidade de estratégia, e sim coordena a jornada do produto do nascimento à maturidade, com foco em aprendizado contínuo, redução de riscos e aceleração segura da inovação. Dentro do ProdOps, o SRE representa uma das engrenagens mais valiosas para viabilizar a operação moderna orientada a dados, fluxos e valor — especialmente em ambientes distribuídos e com múltiplos times colaborando em ritmo contínuo.
Quando a Burocracia é Necessária, mas a Inovação é Inadiável
O ITIL (Information Technology Infrastructure Library) é uma das abordagens mais consolidadas para a gestão de serviços de TI, especialmente em grandes organizações que operam sob rigorosos requisitos de compliance, auditoria e segurança regulatória. Embora não seja popular no ecossistema das startups — por sua reputação de ser excessivamente burocrático — o fato é que todas as empresas, em algum momento da jornada de crescimento ou aquisição, acabam sendo expostas à necessidade de implementar seus princípios, especialmente ao buscar escala, conformidade ou inserção em setores regulados.
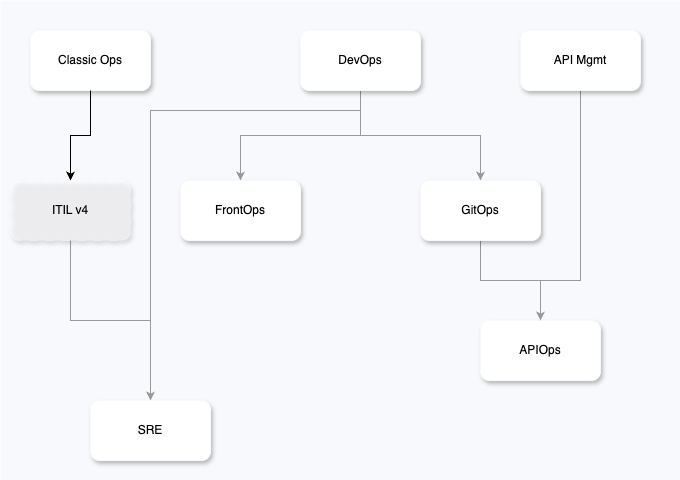
Em indústrias como o mercado financeiro, telecomunicações ou saúde, as exigências legais e normativas impõem práticas como gestão formal de mudanças, segregação de funções, controle de acessos supervisionados e processos de aprovação por múltiplas camadas organizacionais. Nesses contextos, o ITIL oferece a estrutura necessária para garantir rastreabilidade, responsabilidade e governança.
Contudo, o modelo tradicional do ITIL — especialmente nas versões anteriores à v4 — tende a ser interpretado como rígido e lento, dificultando a resposta rápida às mudanças de mercado, um fator crítico em empresas que estão em transformação digital. Por isso, a evolução do ITIL para a versão v4 trouxe uma tentativa significativa de modernização: ela introduziu o conceito de Value Stream, maior foco em colaboração entre equipes e integração com práticas modernas como Lean, Agile e SRE (Site Reliability Engineering).
No entanto, o desafio é que grande parte dos profissionais certificados ou formados sob as versões anteriores do ITIL continuam operando com uma mentalidade baseada em silos e controle excessivo, o que contrasta com os princípios de autonomia, experimentação e entrega contínua do SRE. Mesmo aqueles que atualizaram sua certificação para a ITIL v4 muitas vezes não vivenciaram, na prática, o modelo SRE, e por isso não desenvolveram a abstração necessária para entender como os dois mundos podem coexistir.
Nesse cenário, o papel do Engenheiro de Confiabilidade ProdOps (PRE) torna-se ainda mais relevante: ele atua como tradutor entre a governança tradicional e os modelos modernos de operação, garantindo que o rigor necessário seja mantido — especialmente em ambientes regulados — sem abrir mão da agilidade, automação e confiabilidade contínua exigidas pelo produto digital.
ITIL v4 só é possível com Continuous Delivery
A conformidade total com o ITIL v4 só pode ser alcançada com a adoção da abordagem de Continuous Delivery (CD), pois a estrutura do ITIL v4 enfatiza a entrega de valor contínuo, a resiliência operacional e a colaboração ágil entre equipes. O Continuous Delivery garante que as mudanças no software sejam frequentes, confiáveis e alinhadas com as necessidades do negócio, garantindo a otimização do fluxo de valor de ponta a ponta.
- Foco em Valor e Co-Criação Contínua
- O ITIL v4 enfatiza que as organizações devem entregar valor continuamente aos stakeholders. A prática de CD permite lançamentos frequentes e incrementais, garantindo que os serviços estejam sempre alinhados às expectativas do cliente.
- ITIL v4, Seção Guiding Principles: “Focus on value: Everything the organization does should link back, directly or indirectly, to value for stakeholders.”
- Melhoria Contínua e Resiliência Operacional
- O princípio de “Progress iteratively with feedback” do ITIL v4 incentiva ciclos curtos de desenvolvimento e entrega, o que é fundamental para Continuous Delivery.
- A abordagem de CD permite a detecção e mitigação rápida de falhas, aumentando a resiliência operacional por meio de testes automatizados e implantações seguras.
- ITIL v4, Seção Guiding Principles: “Progress iteratively with feedback: Working in a time-boxed and iterative manner enables fast learning, early risk mitigation, and better responsiveness to change.”
- Gestão de Mudanças Ágil e Automatizada
- A prática de Change Enablement no ITIL v4 recomenda que as mudanças sejam ágeis e bem controladas. Continuous Delivery automatiza a implementação de mudanças, reduzindo riscos e tempo de aprovação.
- ITIL v4, Seção Change Enablement Practice: “Change enablement should balance the need to make beneficial changes and to protect customers and users from the adverse effect of changes.” “Automation and CI/CD pipelines help streamline the change process, reducing lead times and risk.”
- Otimização do Fluxo de Trabalho e Redução de Desperdício
- O ITIL v4 introduz o conceito de Value Streams & Practices, que destaca a necessidade de um fluxo contínuo de entrega de valor. O Continuous Delivery elimina gargalos e desperdícios, garantindo que as entregas sejam ágeis e eficientes.
- ITIL v4, Seção Value Streams & Practices: “Organizations should focus on optimizing the flow of work and removing waste to improve service delivery.”
A adoção de Continuous Delivery não é apenas uma recomendação, mas uma necessidade para alcançar plena conformidade com o ITIL v4. A estrutura do ITIL v4 exige entregas frequentes, automação, resiliência operacional e otimização contínua do fluxo de valor, características inerentes ao CD. Sem essa abordagem, uma organização enfrentaria desafios na gestão ágil de mudanças, mitigação rápida de riscos e entrega contínua de valor, comprometendo sua conformidade total com os princípios do ITIL v4.
O que mudou no CAB no ITIL v4?
No ITIL v4, o Change Advisory Board (CAB), tradicionalmente responsável por avaliar e aprovar mudanças no ITIL v3, perde protagonismo e não é mais um requisito obrigatório. A abordagem do ITIL v4 prioriza a agilidade, automação e descentralização da tomada de decisões dentro da prática de Change Enablement.
Menos burocracia, mais agilidade
No ITIL v3, o CAB era uma estrutura formal que se reunia periodicamente para avaliar mudanças, o que frequentemente gerava atrasos.
No ITIL v4, a ênfase está em tomadas de decisão mais descentralizadas e automação, tornando o CAB opcional e usado apenas em mudanças de alto risco.
Uso de Automação e CI/CD
O ITIL v4 reconhece que processos manuais de aprovação são um gargalo. Ele sugere integração com práticas de DevOps e Continuous Delivery (CD) para mudanças frequentes e de baixo risco.
ITIL v4, Seção Change Enablement: “Automation, self-service, and peer review processes help reduce delays and improve the speed and efficiency of change enablement.”
Tomada de decisão distribuída
Em vez de um único comitê formal (CAB), as decisões de mudança podem ser distribuídas entre diferentes equipes e níveis de responsabilidade.
Mudanças preditivas e automatizadas podem ser aprovadas automaticamente por pipelines de CI/CD, enquanto mudanças de maior risco ainda podem ser analisadas por um grupo especializado.
ITIL v4, Seção Change Enablement: “Change enablement should be tailored to the type and risk level of changes, ensuring faster and more efficient approvals.”
Foco na gestão do risco, não na burocracia
O papel do CAB não desaparece completamente, mas seu foco muda: em vez de aprovar todas as mudanças, ele pode ser acionado apenas para mudanças críticas e de alto impacto.
ITIL v4, Seção Change Enablement: “High-risk changes may still require formal governance, but low-risk changes should be handled through automation or delegated authority.”
Case Magazine Siará
Este artigo adota uma abordagem diferente das anteriores: em vez de explorar conceitos de forma teórica, vamos analisar um case prático de uma empresa fictícia — porém inspirada em situações reais — para ilustrar, na prática, como atua um Engenheiro de Confiabilidade ProdOps (PRE).
Nosso objetivo é mostrar, de forma contextualizada, como o PRE navega por cenários complexos, conecta áreas técnicas e de negócio, e entrega confiabilidade de forma estratégica, mesmo em ambientes com legados, restrições e conflitos de prioridade.

A Magazine Siará é uma empresa de varejo multissetorial que embarcou em sua jornada de transformação digital há alguns anos. Desde então, avançou em diversas frentes, modernizou parte de sua operação e testou praticamente todas as tendências tecnológicas dos últimos dez anos. No entanto, mesmo com essas tentativas de modernização, a empresa ainda não conseguiu atingir um nível sustentável de agilidade e entrega contínua. O desejo de acelerar novos negócios e atualizar sua base tecnológica nunca se converteu em uma estrutura realmente confiável e escalável.
Um dos maiores entraves ainda é o alinhamento entre áreas de negócio e tecnologia, que continua marcado por ruído, retrabalho e prioridades desconectadas. Para tentar equilibrar velocidade com estabilidade, a empresa decidiu, anos atrás, dividir sua TI em duas frentes:
- TI Digital, responsável por acelerar novos produtos e canais.
- TI Legada, que mantém sistemas críticos — incluindo um mainframe — que sustenta operações de loja e integrações com o e-commerce.
Confiabilidade em um Cenário de Fricção entre Velocidade e Legado
Essa divisão foi útil no curto prazo, mas, com o tempo, gerou uma dicotomia de velocidades, onde o legado evolui lentamente, enquanto o digital avança com menos previsibilidade e muita dependência externa. O núcleo digital, por exemplo, passou os últimos anos tentando quebrar um monólito central em microserviços, tanto para escalar seus times quanto para viabilizar a contratação de consultorias — que, sem estrutura clara, acabaram gerando dispersão e perda de controle arquitetural.
O problema central está no descompasso:
➤ Os negócios avançam mais rápido do que a capacidade de estabilização da base técnica.
➤ As dívidas se acumulam, e cada novo projeto coloca ainda mais pressão sobre um sistema que já não aguenta.
A liderança agora enfrenta uma encruzilhada. Há uma enorme pressão do mercado financeiro para realizar uma Black Friday impecável, com impacto direto na percepção de valor da empresa. Ao mesmo tempo, precisa demonstrar vitalidade estratégica, e decidiu lançar uma nova unidade de negócios (BU) de Social Commerce, apostando em uma plataforma de compras em grupo para competir com players asiáticos.
É nesse cenário de urgência, fragmentação e alto risco que entra a figura do Engenheiro de Confiabilidade ProdOps (PRE) — responsável por articular confiança entre legado e inovação, criar visibilidade técnica real para tomada de decisão, e estruturar a base de confiabilidade que permite inovar sem comprometer a operação.
Nova Gestão

Para enfrentar esse momento decisivo, a Magazine Siará tomou uma medida ousada: contratou Joey Feitosa como Diretor de Digital, um executivo com ampla experiência em estratégias de ProdOps e histórico de sucesso em cenários complexos de transformação. Joey foi trazido com duas missões prioritárias:
- Entregar a melhor Black Friday da história da empresa, com estabilidade, performance e visibilidade fim a fim.
- Garantir que a nova BU de Social Commerce não comprometa a operação atual, mas sim atue como uma alavanca de inovação sustentável.
Sabendo que não bastava acelerar entregas sem garantir confiabilidade, Joey trouxe consigo John Moreira, um especialista em engenharia de confiabilidade moderna, para liderar a frente de PRE – ProdOps Reliability Engineering. John assumiu o desafio de estruturar tecnicamente a missão, atuando como elo entre legado, digital, negócio e times de plataforma.
Ao assumir a frente de PRE, John deixou claro que o sucesso da Black Friday e da nova BU não dependia apenas de ferramentas ou mais squads, mas de um plano estruturado de confiabilidade, sustentado por quatro eixos:
- Observabilidade em primeiro lugar – garantir que todos os fluxos críticos, APIs, integrações e jornadas do cliente sejam visíveis, rastreáveis e diagnosticáveis antes que o problema chegue ao cliente.
- Matriz de Confiabilidade – mapear riscos técnicos e operacionais com foco nos componentes mais sensíveis da operação, como o mainframe e os pontos de integração com o e-commerce.
- SLOs com o negócio – alinhar expectativas reais com a diretoria e product owners, transformando ansiedade por entrega em acordos objetivos baseados em impacto.
- Redução de TOIL e ruído técnico – priorizar automações, padronizações e ajustes estruturais para que a operação flua mesmo com aumento de carga e iniciativas simultâneas.
Com um time técnico já sobrecarregado e um legado altamente acoplado, John sabia que não haveria tempo para grandes reestruturações, mas havia espaço para clareza, foco e melhoria contínua guiada por dados. Sua primeira ação foi implementar um modelo de observabilidade pragmática, criando um ambiente informativo que permitisse antecipar falhas, monitorar gargalos e dar visibilidade ao que antes era invisível.
Com Joey no comando estratégico e John cuidando da engenharia de confiabilidade, a Magazine Siará começou a construir — não apenas a melhor Black Friday de sua história — mas também as fundações técnicas de uma nova fase, onde o digital cresce com segurança, e a inovação deixa de ser risco para se tornar diferencial competitivo.
Narrativa da companhia
Nos vídeos divulgados sobre o princípio “Observabilidade em Primeiro Lugar”, é possível acompanhar como Joey Feitosa e, principalmente, John Moreira atuaram estrategicamente para dar os primeiros passos rumo ao sucesso da missão da Magazine Siará. Com base no framework ProdOps, eles iniciaram a construção de uma narrativa clara sobre o estado atual da companhia, transformando ruídos e suposições em visibilidade objetiva e acionável.
A atuação de John foi decisiva: ele não partiu de premissas técnicas abstratas, mas começou pelo que realmente importa — entender o que o negócio precisava enxergar para tomar decisões com segurança, e o que os times precisavam observar para operar com fluidez e confiança. Essa abordagem permitiu estabelecer um ambiente informativo, onde todos — da liderança à operação — passaram a ter uma leitura compartilhada dos riscos, capacidades e gargalos do ecossistema técnico.
A partir dessa base, o processo de confiabilidade deixou de ser reativo e se tornou coordenado, alinhando estratégia, execução e aprendizado contínuo. O conteúdo dos vídeos revela não apenas ferramentas ou práticas, mas a mudança de postura necessária para transformar observabilidade em valor organizacional concreto — um passo essencial para enfrentar desafios como uma Black Friday histórica e o lançamento de uma nova unidade de negócios em paralelo.
Plano de Confiabilidade para a Black Friday
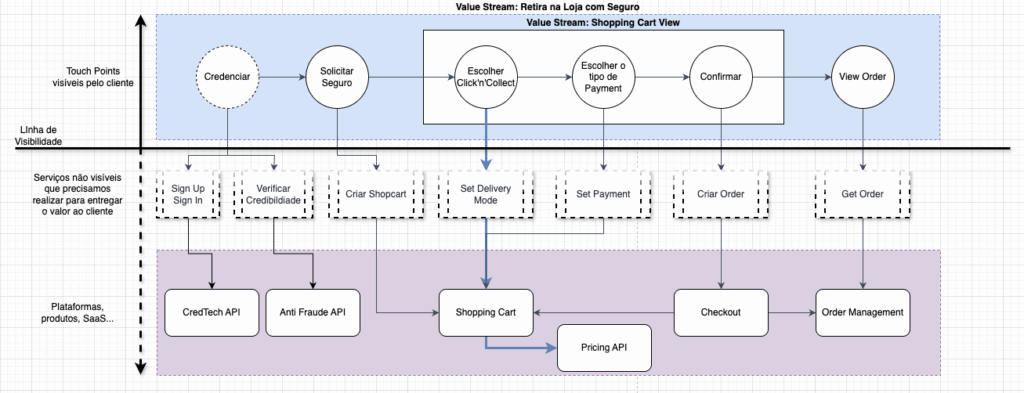
Após conduzir a primeira rodada do Assessment Contínuo de Confiabilidade, John Moreira deu início à construção de um plano específico para a Black Friday, alinhado ao cenário crítico da Magazine Siará. Sua primeira iniciativa foi mapear o Roadmap dos times de produto, buscando entender os objetivos de negócio e as entregas previstas — não apenas do ponto de vista de escopo, mas também de viabilidade técnica, riscos e interdependências reais.
Com base em uma dinâmica de Premortem, John liderou uma análise detalhada que antecipava possíveis pontos de falha, gargalos de integração e falhas operacionais que poderiam comprometer o evento. A partir desse exercício, foi possível transformar incertezas em oportunidades de planejamento técnico proativo, redefinindo o foco das entregas para que as peças certas estivessem disponíveis no momento certo, garantindo viabilidade real — e não apenas promessas de entrega.
Jornada de Diligência Contínua
Desse processo emergiram dois grandes pilares estratégicos, que além de sustentarem a Black Friday, resolveriam dores históricas da companhia e criariam a fundação para a evolução futura:
1. Modelo de Setup e Onboarding Técnico Eficiente
Um dos maiores entraves da empresa era o tempo excessivo para onboarding de novos colaboradores, terceiros e consultorias. Profissionais demoravam até dois meses para obter todos os acessos, entender o ecossistema e atingir produtividade plena.
John liderou a criação de um modelo de setup padronizado, com foco em:
- Provisionamento automático de acessos e ambientes, com uso de IaC (Infrastructure as Code).
- Documentação mínima e orientada por contexto, não apenas por sistemas.
- Ferramentas de autoatendimento e rastreabilidade do progresso.
Esse modelo não só acelerou a integração de novos membros, mas reduziu drasticamente o atrito entre áreas técnicas e de compliance, criando um fluxo mais saudável para adição de capacidade em momentos críticos.
2. Fundamento para Dados e Modelagem Guiada por Domínio
A segunda entrega estratégica foi estruturar um modelo de dados e serviços mais alinhado ao negócio, com base nos princípios de Domain-Driven Design (DDD). Até então, as decisões sobre onde colocar funcionalidades ou lógicas de negócio eram feitas por conveniência técnica, sem clareza sobre fronteiras de domínio ou responsabilidades.
John propôs:
- Mapeamento de transações de negócio entre serviços existentes, com base em observabilidade e rastreamento.
- Definição de quais serviços deveriam herdar ou expor essas transações, respeitando o limite dos domínios.
- Aplicação de Test-Driven Development (TDD) adaptado à infraestrutura moderna, com foco em testes integrados (e não apenas unitários), refletindo as práticas de ambientes distribuídos e orquestrados via containers.
Esse novo arranjo técnico não apenas fortaleceu o dia a dia dos times, mas também permitiu criar dados confiáveis sobre o comportamento do negócio em produção, melhorando análises, tomada de decisão e priorização futura.
Como John transformou setup, operação e confiança em um só movimento técnico
No coração da preparação para a Black Friday da Magazine Siará, John Moreira identificou um gargalo invisível, mas crítico: os desenvolvedores não tinham um ambiente de trabalho que refletisse a realidade operacional de suas squads.
A maioria trabalhava com mocks, containers genéricos ou um “ambiente local” mal documentado, que pouco ou nada tinha a ver com o comportamento real dos serviços em produção. Isso comprometia não só a qualidade das entregas, mas também a autonomia do time para entender falhas, diagnosticar erros e tomar decisões confiáveis.
Foi então que John propôs algo ousado: transformar o setup de desenvolvimento em uma simulação realista da operação da squad, com uso intensivo de Infrastructure as Code (IaC), observabilidade distribuída e integração com ferramentas de monitoramento que antes só existiam em produção.
O plano era mais do que rodar containers. Era criar um blueprint funcional da squad, onde o desenvolvedor pudesse, com um único comando, subir:
- Seus 5 principais repositórios em modo watch para desenvolvimento iterativo.
- Um ambiente com observabilidade distribuída completa, replicando a topologia de produção.
- Integração com o New Relic no ambiente de desenvolvimento, para visualizar tracing, métricas e logs ao vivo, como se estivesse em produção — mas com segurança e controle total.
Esse modelo rompeu uma barreira cultural: os times passaram a enxergar observabilidade como ferramenta de design, não de suporte, e os próprios devs — inclusive os juniores — começaram a atuar com clareza e confiança no diagnóstico de erros, comportamento anômalo e performance, chegando a realizar troubleshooting de nível L3.
Além disso, a entrega já saía instrumentada corretamente, sem depender de ajustes de última hora em homologação ou produção.
Roadmap Técnico da Iniciativa
🗓️ Semana 1: Diagnóstico e modelagem inicial
- Mapeamento dos serviços de uma squad
- Identificação das dependências entre repositórios
- Avaliação do que precisava ser simulado via IaC (filas, banco, gateways, observability stack)
🗓️ Semana 2: Estruturação do setup por squad
- Definição de templates com Terraform/Docker Compose customizados para contexto da squad
- Padronização da criação de .env, secrets e configurações locais
🗓️ Semana 3: Integração de observabilidade em dev
- Instalação e configuração do New Relic em modo dev com policies adaptadas
- Criação de dashboards locais para métricas e tracing com alertas simulados
- Integração de logs estruturados com contexto de transação, request ID e domínio
🗓️ Semana 4: Testes guiados e refinamento
- Teste com a squad-piloto em operações reais
- Feedbacks dos devs para ajustar performance, peso do ambiente e facilidade de uso
- Criação de um comando único (make dev-ready) para automatizar o processo
🗓️ Semana 5: RELEASE + rollout
- Documentação prática e visual do processo
- Sessões hands-on: “Como diagnosticar sua aplicação como um L3”
- Rollout do setup para todas as squads envolvidas na Black Friday
Esse movimento, liderado por John, não apenas elevou a maturidade técnica da companhia, como reforçou o princípio central do ProdOps: observabilidade em primeiro lugar e confiabilidade como cultura, não como etapa.
resultados VERIFICADOS
- Redução do tempo médio de setup de ambiente local de 2 dias para 30 minutos
- Entrega 100% já instrumentada
- Queda de 60% nas dependências do time de SRE para investigação de bugs
- Desenvolvedores júnior atuando com autonomia em incidentes simulados
Além do impacto direto na squad-piloto, o plano arquitetado por John Moreira foi estrategicamente desenhado para ser escalável de forma incremental e segura. Cada fase concluída com sucesso servia como base reutilizável para outras squads, respeitando as particularidades de cada time, mas mantendo um núcleo comum de práticas, ferramentas e princípios.
Com os primeiros resultados validados — incluindo a redução drástica do tempo de onboarding, o aumento da autonomia técnica dos devs e o ganho de visibilidade no comportamento das aplicações — Joey Feitosa autorizou a expansão controlada do modelo, o que permitiu a formação de duas squads auxiliares de ProdOps para acelerar o rollout.
Esses times auxiliaram na:
- Adaptação do setup para outras realidades técnicas (ex: squads com front-end separado, ou que dependem de integrações legadas).
- Documentação viva baseada em aprendizado real, sem recomeçar do zero.
- Criação de um repositório de templates e padrões reutilizáveis, com versionamento e automação contínua via GitOps.
- Facilitação de workshops técnicos e suporte direto durante as primeiras implantações em novas squads.
Essa estratégia de escala progressiva com validação em tempo real permitiu que o plano evoluísse de uma boa prática isolada para um modelo institucional de confiabilidade técnica e operacional, criando um efeito de rede: quanto mais squads adotavam, mais valor era gerado coletivamente — tanto em qualidade quanto em capacidade de resposta organizacional.
Em poucas semanas, o que começou como uma medida para preparar a Black Friday tornou-se um ativo estratégico reutilizável para qualquer nova iniciativa da Magazine Siará, inclusive para a recém-criada BU de Social Commerce, que pôde nascer sobre uma fundação técnica muito mais confiável e observável desde o primeiro commit.
O PRE como figura central da confiabilidade contínua
O Engenheiro de Confiabilidade ProdOps (PRE) é um profissional multifacetado, adaptável e profundamente estratégico. Sua principal força está em criar planos de confiabilidade sob medida, ajustados ao momento do negócio, à maturidade do produto e à realidade dos times e clientes envolvidos. Ele não trabalha com modelos engessados, mas com frameworks evolutivos, construindo soluções que respeitam o legado, exploram o que já está disponível e ampliam a visibilidade e a autonomia organizacional.
Mais do que mitigar riscos, o PRE ativa a inovação com segurança, harmonizando operações técnicas com estratégias de produto, e tornando a confiabilidade parte do fluxo natural de entrega, e não uma barreira final.
Tabela Comparativa: Evolução do SRE para o PRE
| Dimensão | SRE (Site Reliability Engineer) | PRE (ProdOps Reliability Engineer) |
|---|---|---|
| Origem | Criado pelo Google como modelo técnico-operacional de confiabilidade. | Evolução do SRE com integração plena a produto, negócio e práticas ProdOps. |
| Foco principal | Manter sistemas escaláveis e altamente disponíveis. | Construir planos de confiabilidade ajustados ao contexto e ao ciclo de vida do produto. |
| Atuação | Sustentação e performance de plataformas em larga escala. | Atua em produto, operações, dados, onboarding, fluxo e observabilidade de ponta a ponta. |
| Abordagem técnica | SLIs, SLOs, automação de tarefas (TOIL), gestão de erro e incidentes. | Observabilidade em primeiro lugar, integração com squads, modelos de setup e diagnóstico. |
| Ligação com produto | Indireta – foca em confiabilidade da plataforma. | Direta – participa do discovery, valida requisitos não funcionais e define critérios operacionais. |
| Escalabilidade da prática | Alta, porém exige times dedicados ou grandes estruturas. | Altamente escalável e pragmático – atua com o que a empresa já tem, como no Kanban. |
| Governança e processos | Fortemente técnico com práticas ágeis complementares. | Integra práticas ágeis com governança leve, útil inclusive para ambientes regulados. |
| Atuação em legados | Possível, mas com esforço técnico e reorganizacional. | Especialista em atuar sem reestruturação – valoriza clareza, visibilidade e entrega evolutiva. |
| Ponto forte | Estabilidade e performance técnica em larga escala. | Visão sistêmica e adaptabilidade em ciclos de produto, com forte alinhamento de negócio. |
Deixe um comentário
Você precisa fazer o login para publicar um comentário.